


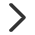

 扫码支付更轻松
扫码支付更轻松

1. 功能
代谢物差异分析就是找出两组样本间差异表达的代谢物。差异代谢物分析在代谢组研究中有着重要的作用,通过寻找两组间的差异代谢物,可研究与生理病理变化相关的代谢物与代谢通路。
差异代谢物的筛选通常采取结合单变量统计分析和多变量统计分析的方法。因为代谢组数据具有“高维、高噪声、高变异”的特点,因此多元统计分析被广泛应用于差异代谢物分析中,可更好地揭示不同代谢物之间的关系,挖掘两组样本之间差异的代谢物。在采用多变量统计分析的同时,结合T检验的单变量统计分析,可以避免只使用一类统计分析方法带来的假阳性错误或模型过拟合,有助于得到更准确的分析结果。

2. 输入
文件格式:支持txt(制表符分隔)文本文件、csv(逗号分隔)文本文件、以及Excel专用的xlsx格式,同样支持旧版Excel的xls(Excel 97-2003 )格式。
输入数据:需要提供代谢物定量表、分组信息及组间比较三个数据文件:
1)代谢物定量表
输入文件的第一行为样本ID,第一列为代谢物ID,表中的数值为每个样本的代谢物相对定量值。

2)分组信息文件
定义分组信息。第一列为样本名,第二列为所在的组名。注意:即使没有实验重复,依然需要填写这个文件(1个样本为1组)。但不建议不做重复。

3)组间比较文件
列出要进行差异分析的比较组的文件。第一列为对照组,第二列为处理组,在进行差异分析时是第二列比上第一列。一行为一个比较组。

3. 参数
1)差异检验方法
选择用来进行差异分析的多变量统计方法。我们提供PLS-DA和OPLS-DA两种方法,两种方法只能选一种。偏最小二乘判别分析(PLS-DA)是一种有监督模式识别的多元统计分析方法,将多维数据在压缩前先按需要寻找的差异因素分组(预先设定Y值来进行目标分类和判别),这样可以找到与用于分组的因素最相关的变量,而减少一些其它因素的影响。正交偏最小二乘判别分析(OPLS-DA)结合了正交信号矫正(OSC)和PLS-DA方法,能够将X矩阵信息分解成与Y相关和不相关的两类信息,通过去除不相关的差异来筛选差异变量。因此OPLS-DA解释能力更强,可更准确地筛选出组间差异。与PCA分析相比,(O)PLS-DA可以使组间区分最大化,有利于寻找差异代谢物。其中,模型变量的变量权重值(Variable important in projection, VIP)可以衡量各代谢物积累差异对各组样本分类判别的影响强度和解释能力,VIP≥1为常见的差异代谢物筛选标准。
2)P value
单变量统计分析T检测的检验值。我们默认同时采取多变量统计分析和单变量统计分析进行差异代谢物的筛选。一般选择P value<0.05。
3)VIP阈值
VIP(Variable important in projection)是(O)PLS-DA模型变量的变量权重值,可用于衡量各代谢物积累差异对各组样本分类判别的影响强度和解释能力,VIP≥1为常见的差异代谢物筛选标准。
4)差异倍数
在利用多变量统计分析的VIP值和单变量统计分析T检测的P值进行筛选的同时,也可以加上代谢物定量值的差异倍数来进行进一步的筛选。默认1,也就是不考虑差异倍数。
4. 输出
以OPLS-DA差异检验方法为例:
1)diff_stat.xls:差异代谢物统计表
2)diff_stat.png:所有比较组的差异代谢物统计柱状图(标量图)
3)diff_stat.pdf:所有比较组的差异代谢物统计柱状图(矢量图)
4)A-vs-B.all.xls:差异代谢物总表
5)A-vs-B.filter.xls:显著差异代谢物表(达到显著差异阈值)
6)A-vs-B.pca.png:主成分分析(PCA)得分图(标量图)
7)A-vs-B.pca.pdf:主成分分析(PCA)得分图(矢量图)
8)A-vs-B.pc.xls:PCA主成分表
9)A-vs-B.plsda.png:OPLS-DA得分图(标量图)
10)A-vs-B.plsda.pdf:OPLS-DA得分图(矢量图)
11)A-vs-B.permutation.png:OPLS-DA统计模型的排序检验验证图(标量图)
12)A-vs-B.permutation.pdf:OPLS-DA统计模型的排序检验验证图(矢量图)
13)A-vs-B.tmp.Ttest.xls:单变量统计分析结果表
14)A-vs-B.vip.xls:多变量统计模型中每个变量的VIP值表
1. 数据上传与参数选择
按说明准备所需数据,点击“选择文件”上传数据。“项目编号”即为最终结果文件夹名称,可在“项目总览”中查看,项目编号可自行修改或保持默认。
点击工具面板参数,可查看该参数的解释说明。

2. 输出结果
1)差异代谢物统计柱状图:
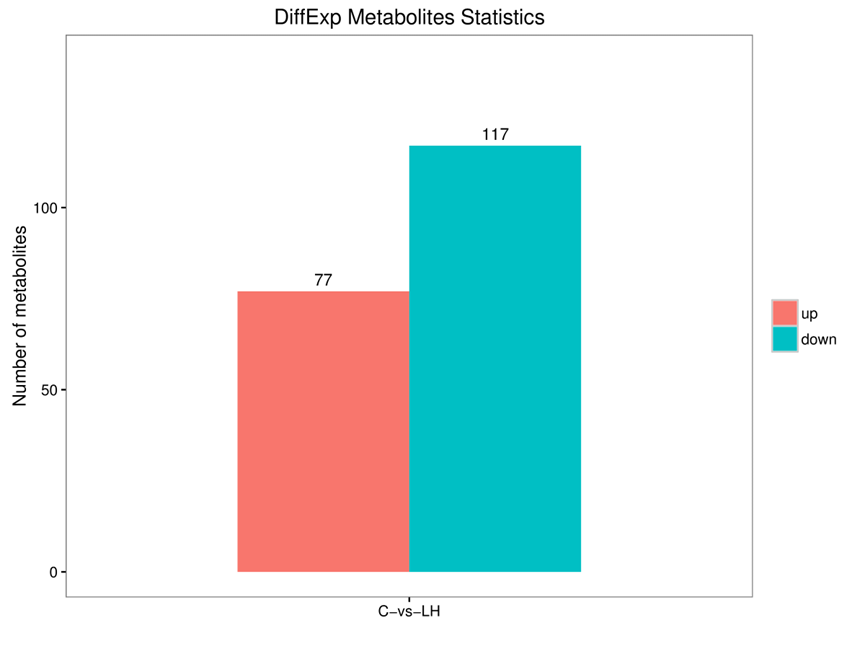
2)PCA得分图:
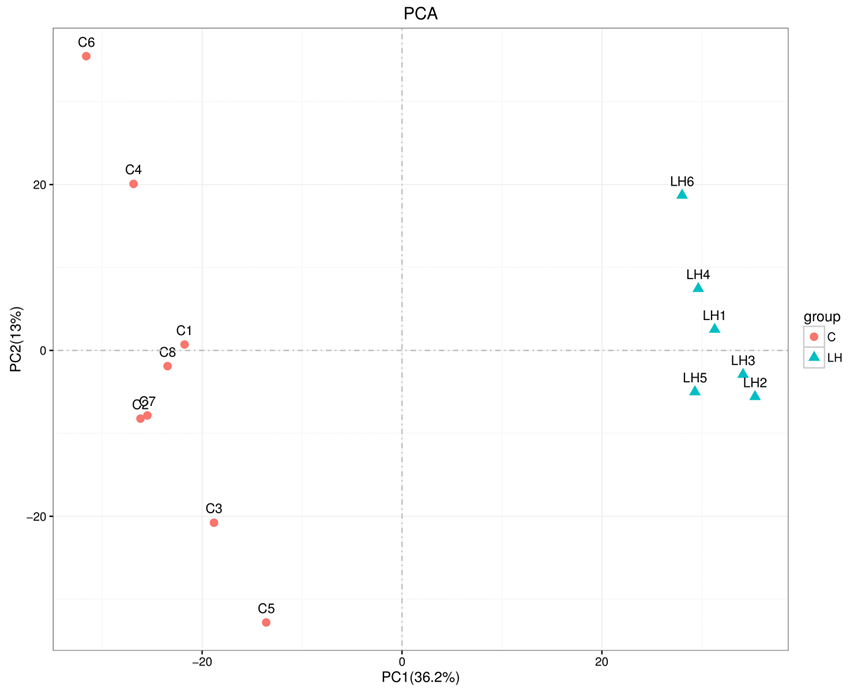
3)OPLS-DA得分图:

4)OPLS-DA统计模型permutation test验证图:

Q1. 上传的数据需要保存成什么格式?文件名称和拓展名有没有要求?
OmicShare当前支持txt(制表符分隔)文本文件、csv(逗号分隔)文本文件、以及Excel专用的xlsx格式,同样支持旧版Excel的xls(Excel 97-2003 )格式。如果是核酸、蛋白序列文件,必须为FASTA格式(本质是文本文件)。
文件名可由英文和数字构成,文件拓展名没有限制,可以是“.txt”、“.xlsx”、“.xls”、“.csv”“.fasta”等,例如 mydata01.txt,gene02.xlsx 。
Q2. 提交时报错常见问题:
1.提交时显示X行X列空行/无数据,请先自查表格中是否存在空格或空行,需要删掉。
2.提交时显示列数只有1列,但表格数据不止1列:列间需要用分隔符隔开,先行检查文件是否用了分隔符。
其它提示报错,请先自行根据提示修改;如果仍然无法提交,可通过左侧导航栏的“联系客服”选项咨询OmicShare客服。
Q3. 提交的任务完成后却不出图该怎么办?
主要原因是上传的数据文件存在特殊符号所致。可参考以下建议逐一排查出错原因:
(1)数据中含中文字符,把中文改成英文;
(2) 数据中含特殊符号,例如 %、NA、+、-、()、空格、科学计数、罗马字母等,去掉特殊符号,将空值用数字“0”替换;
(3)检查数据中是否有空列、空行、重复的行、重复的列,特别是行名(一般为gene id)、列名(一般为样本名)出现重复值,如果有删掉。
排查完之后,重新上传数据、提交任务。如果仍然不出图,可通过左侧导航栏的“联系客服”选项咨询OmicShare客服。
Q4.下载的结果文件用什么软件打开?
OmicShare云平台的结果文件(例如,下图为KEGG富集分析的结果文件)包括两种类型:图片文件和文本文件。

图片文件:
为了便于用户对图片进行后期编辑,OmicShare同时提供位图(png)和矢量图(pdf、svg)两种类型的图片。对于矢量图,最常见的是pdf和svg格式,常用Ai(Adobe illustrator)等进行编辑。其中,svg格式的图片可用网页浏览器打开,也可直接在word、ppt中使用。
文本文件:
文本文件的拓展名主要有4种类型:“.os”、“.xls”、“.log”和“.txt”。这些文件本质上都是制表符分隔的文本文件,使用记事本、Notepad++、EditPlus、Excel等文本编辑器直接打开即可。结果文件中,拓展名为“.os”文件为上传的原始数据;“.xls”文件一般为分析生成的数据表格;“.log”文件为任务运行日志文件,便于检查任务出错原因。
Q5. 提交的任务一直在排队怎么办?
提交任务后都需要排队,1分钟后,点击“任务状态刷新”按钮即可。除了可能需运行数天的注释工具,一般工具数十秒即可出结果,如果超出30分钟仍无结果,请联系OS客服,发送任务编号给OmicShare客服,会有专人为你处理任务问题。
Q6. 结果页面窗口有问题,图表加载不出来怎么办?
尝试用谷歌浏览器登录OmicShare查看结果文件,部分浏览器可能不兼容。
引用OmicShare Tools的参考文献为:
Mu, Hongyan, Jianzhou Chen, Wenjie Huang, Gui Huang, Meiying Deng, Shimiao Hong, Peng Ai, Chuan Gao, and Huangkai Zhou. 2024. “OmicShare tools: a Zero‐Code Interactive Online Platform for Biological Data Analysis and Visualization.” iMeta e228. https://doi.org/10.1002/imt2.228案例1(PLS-DA)
发表期刊:Journal of Functional Foods
影响因子:5.6
发表时间:2021
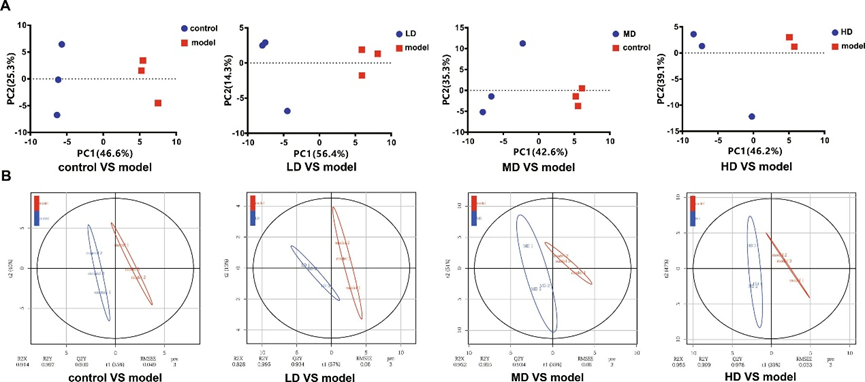
Fig. 7. TO regulates the serum metabolites of mice exposed to CS. (A) PCA of Serum metabolites control vs model, LD vs model, MD vs model, HD vs model. (B) PLS-DA of serum metabolites control vs model, LD vs model, MD vs model, (B4) HD vs model.
引用方式:
Principal component analysis (PCA) analysis and partial least squares discriminant analysis (PLS-DA) analysis were performed using the online OmicShare tools (http://www.omicshare.com/tools).
参考文献:
Chen J, Yi C, Lu C, et al. High DHA tuna oil alleviated cigarette smoking exposure induced lung inflammation via the regulation of gut microbiota and serum metabolites[J]. Journal of Functional Foods, 2021, 82: 104505.
案例2(PLS-DA)
发表期刊:Dose-Response
影响因子:2.5
发表时间:2020

Figure 2. PLS-DA score plots of serum samples from 0 and 8 Gy groups represented by the blue line and red line, respectively, at (A) 6, (B) 24, and (C) 72 hours postradiation. One data point stands for 1 mouse. n = 5 per group. The corresponding R2X, R2Y, and Q2Y values are shown in (A, B, and C), respectively. PLS-DA indicates partial least squares discriminant analysis.
引用方式:
Student t tests, hierarchical clustering analysis, PCA, PLS-DA plots, and Pearson correlation analysis were performed using OmicShare (http://www.omicshare.com/tools).
参考文献:
Huang J, Wang Q, Qi Z, et al. Lipidomic profiling for serum biomarkers in mice exposed to ionizing radiation[J]. Dose-Response, 2020, 18(2): 1559325820914209.