


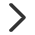

 扫码支付更轻松
扫码支付更轻松

一. 数据整理与上传
①通过“说明”和“示例文件”两处查看所需的数据格式,严格按要求整理。
②输入分组文件。注意:需要以表达量文件/样本坐标文件中的样本为分组(即对应文件第一列)。
点击“选择文件”上传整理好的数据。
二. 参数选择与提交
根据自身需求进行参数选择,详见“说明”部分,其中PCA算法和partial_PCA算法不可同时使用。最后提交任务即可。
三. 结果查看与动态调整
①动态工具点击“预览”或“跳转查看”小图标进入调整界面,进行图形个性化及下载。
②当前工具页下拉选择选择项目编号亦可进入。
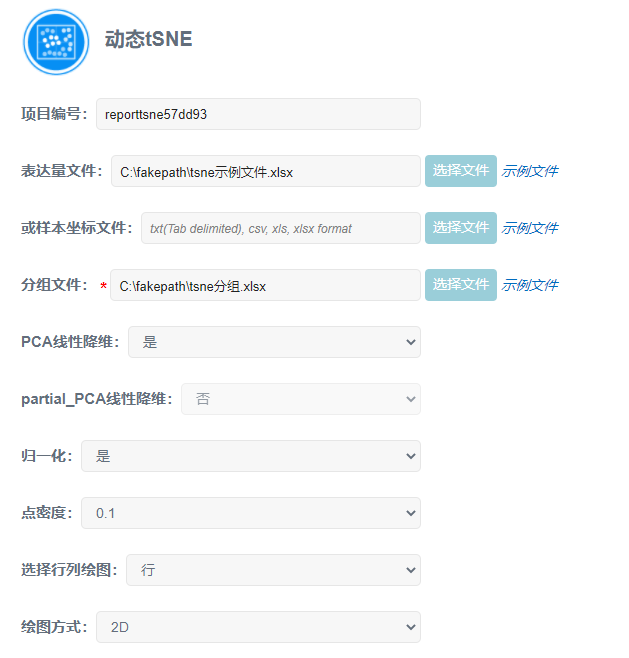
初步图形如下:
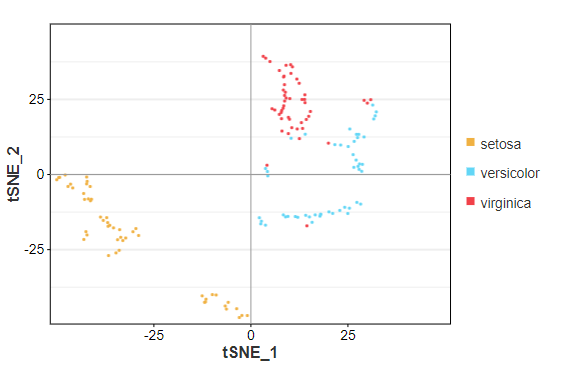
文字样式、颜色修改:
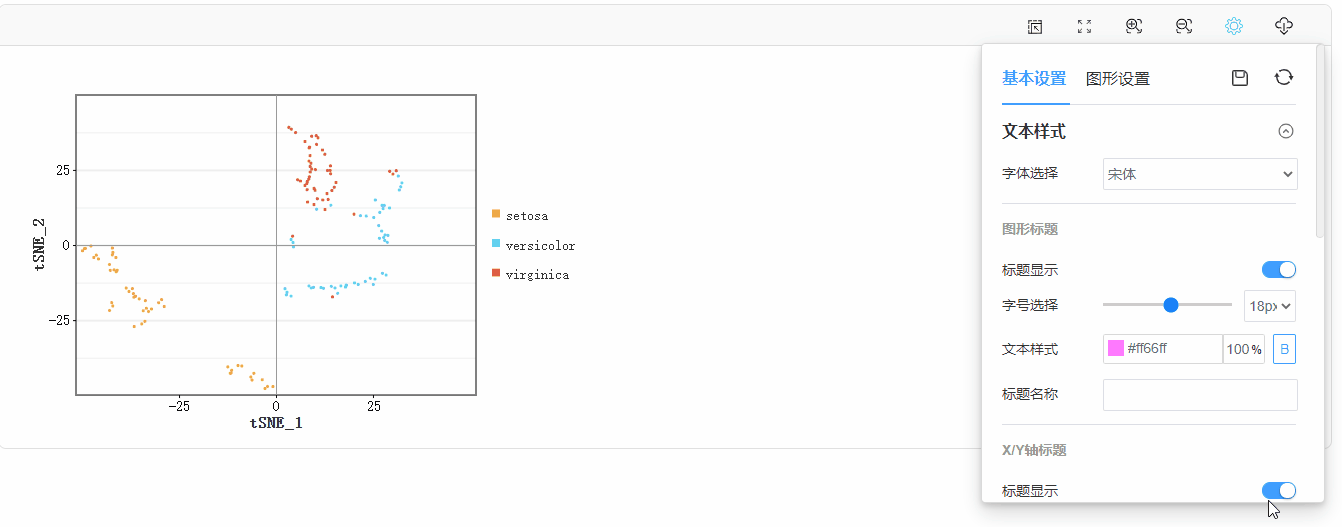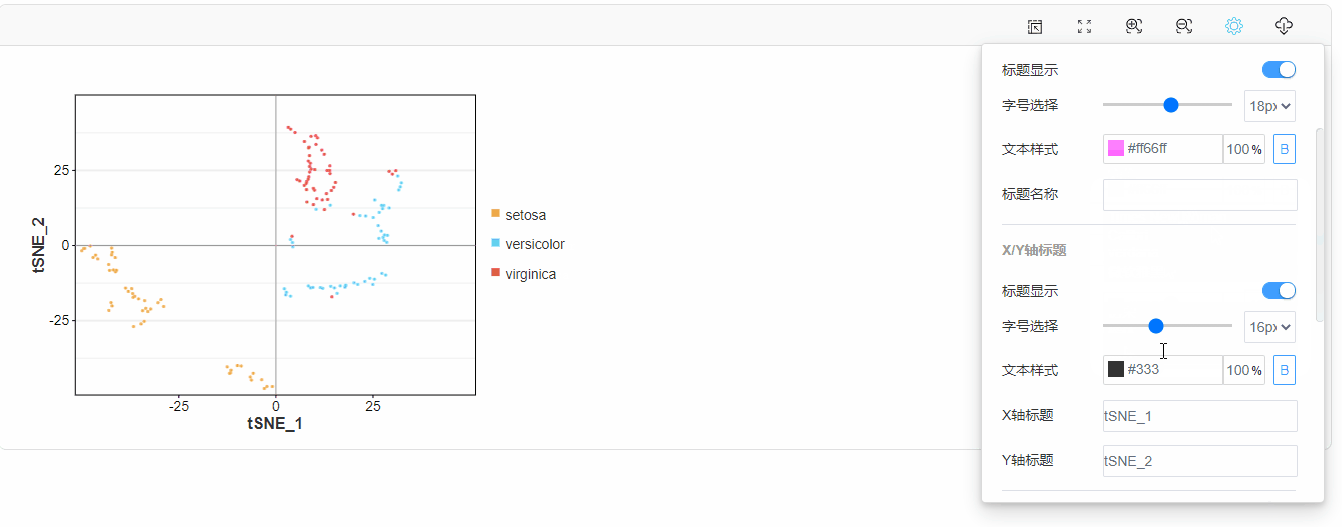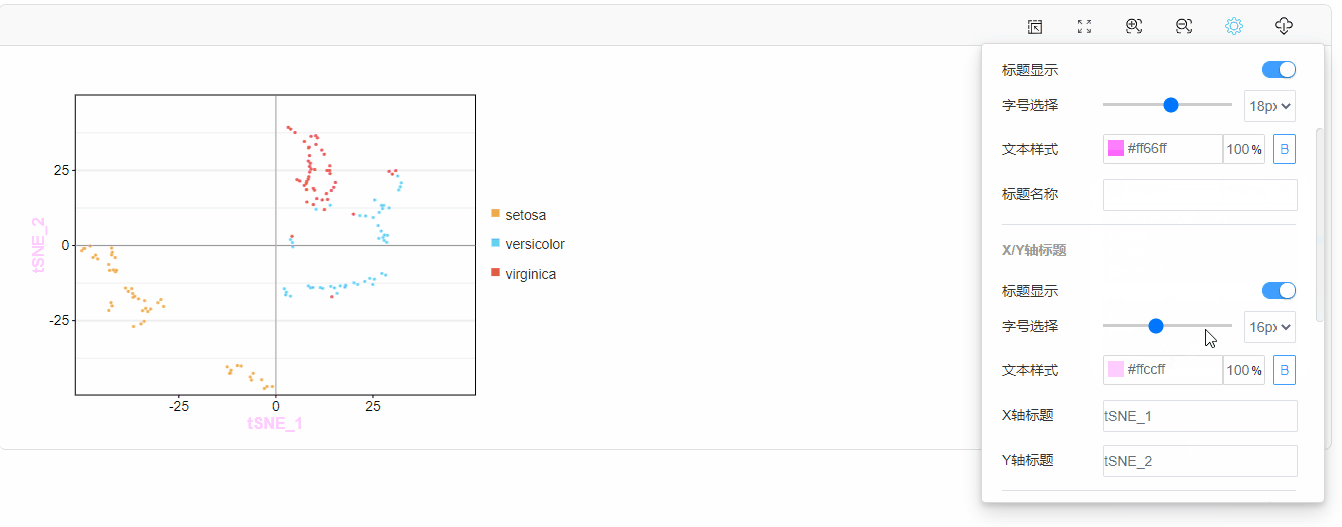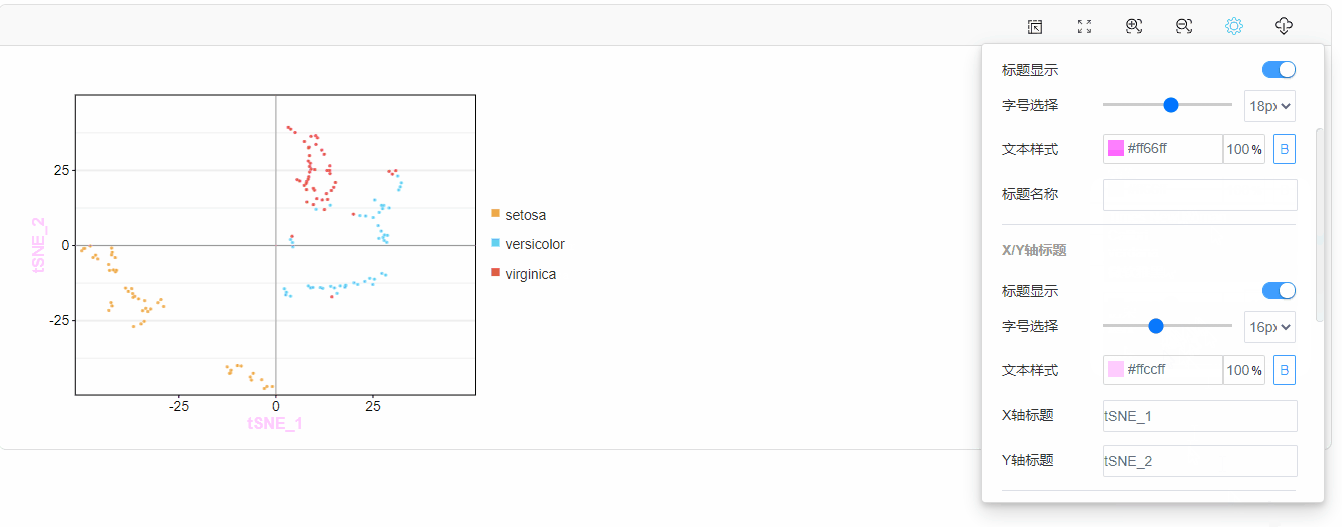
轴线修改:
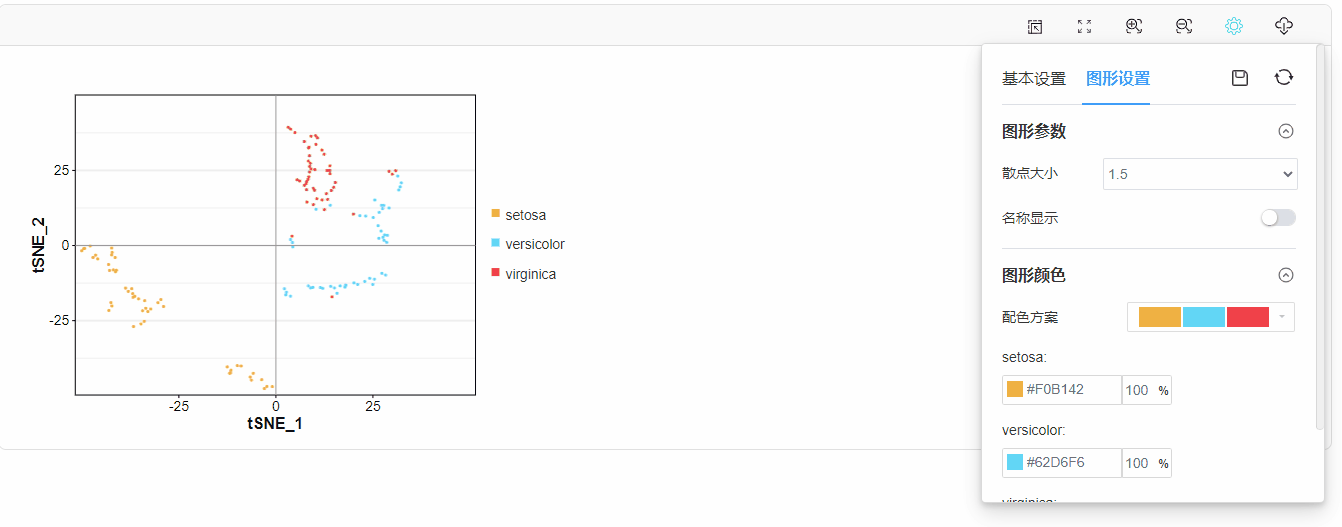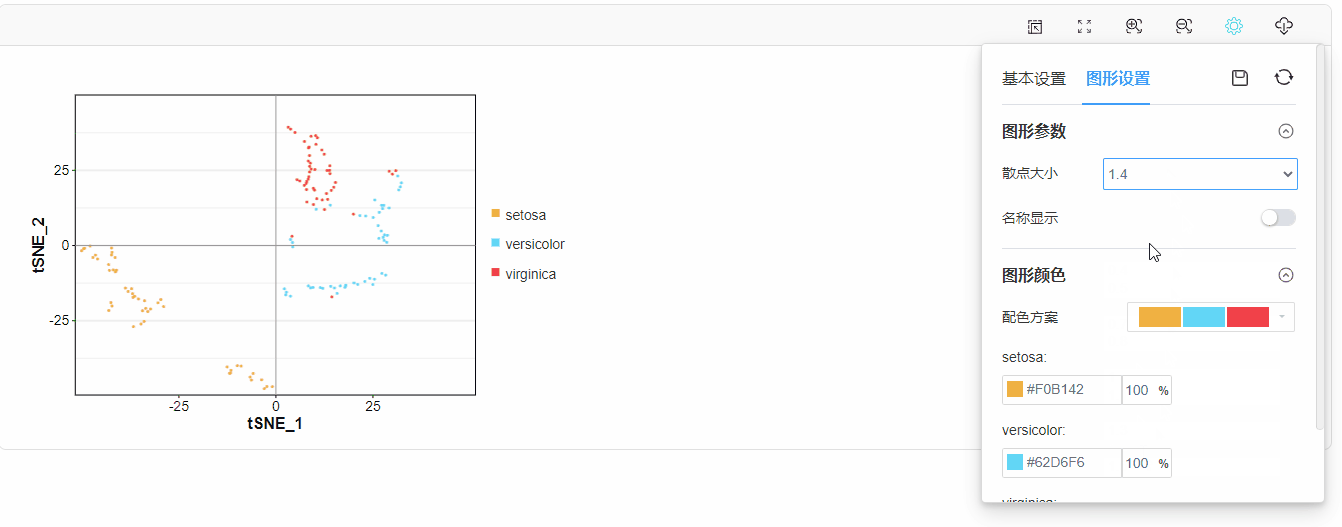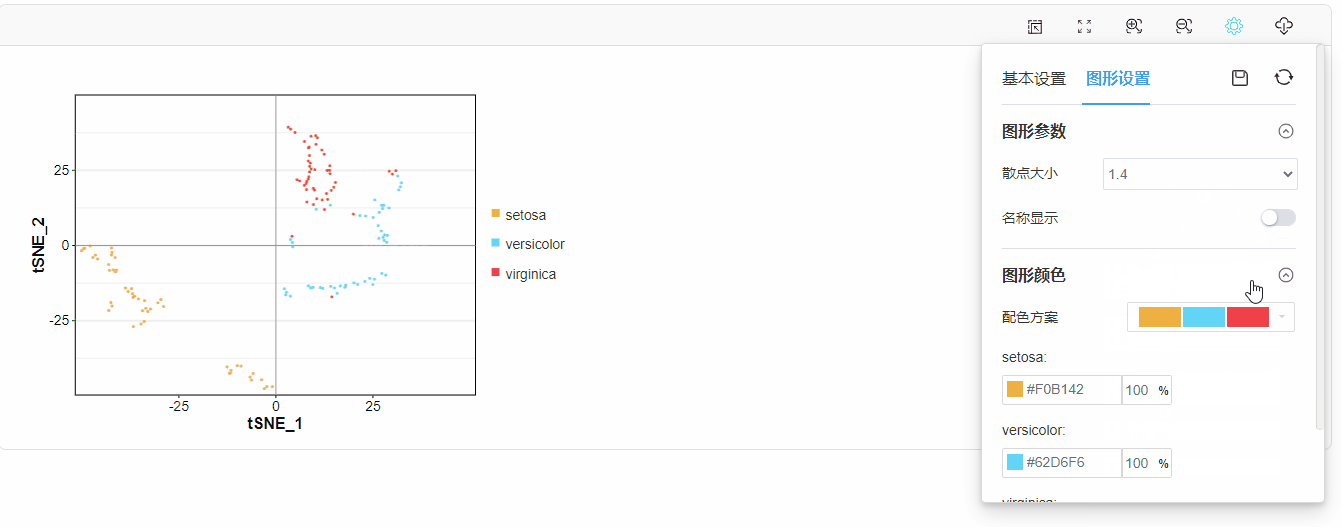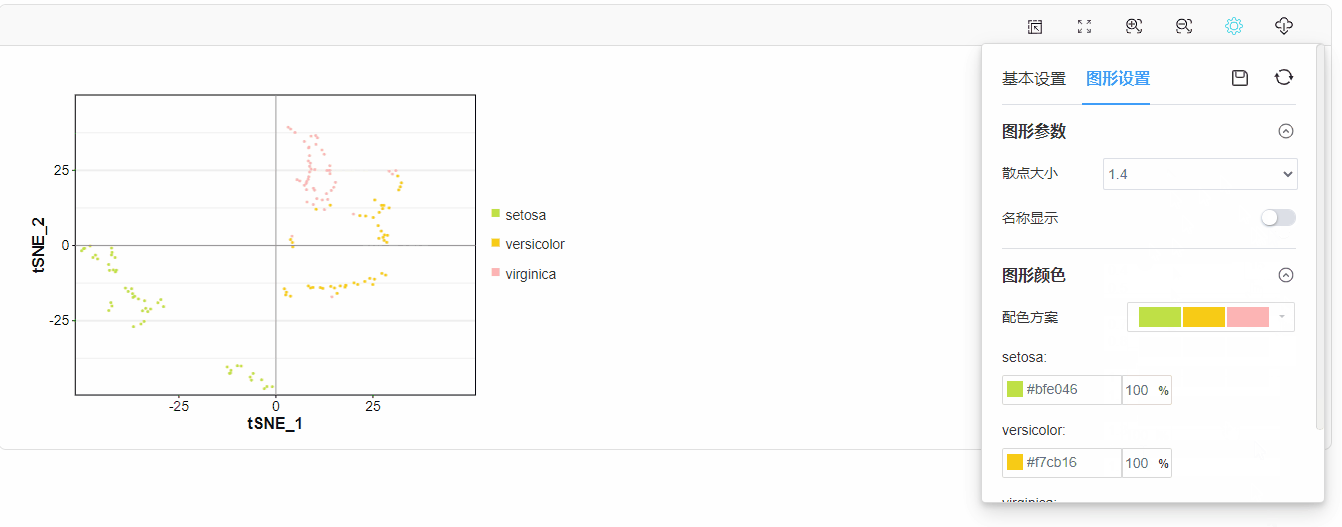
图形样式、配色修改:
四. 结果下载
动态工具在动态调整界面进行下载,可以选择png/svg/pdf格式下载。
其中svg、pdf为矢量图形,可无限放大不模糊。


tSNE图是指经过非线性降维算法t分布随机邻接嵌入(t-distributed Stochastic Neighbor Embedding, tSNE)将高纬度数据投影到二维坐标系中绘制完成的图。tSNE图可以克服线性降维聚类效果差的缺点,夸大样本间的距离关系,使相似度高的样本更为集中,相似度的低的样本更为分散,使数据呈现更好的聚类结果。
(1)模块功能:通过tSNE图动态展示不同样本之间的聚类关系
(2)注意事项:如果使用单细胞转录组数据进行绘图,必须上传分组文件,且保证细胞数目小于10000个
(3)文件输入:
支持txt(制表符分隔)文本文件、csv(逗号分隔)文本文件、以及Excel专用的xlsx格式,同样支持旧版Excel的xls(Excel 97-2003 )格式。文件名可由英文和数字构成,文件拓展名没有限制,可以是“.txt”、“.xlsx”、“.xls”、“.csv” 等,例如 mydata01.txt,gene02.xlsx 。
示例文件1:
(4)分析与操作:
①线性降维:线性降维是对数据的预处理。利用主成分对数据进行tSNE降维,可以有效提高tSNE算法的运算速度。使用partial_PCA算法后运算速度最快,但降维后的精确度最低,建议仅大型数据时使用。PCA算法和partial_PCA算法不可同时使用;
②归一化:我们利用z-score进行数据的归一化,即将每个基因的表达量减去这个基因在所有样本中表达量的均值,然后除以其标准差。对数据进行归一化,可消除表达量异常高的基因的影响,减少数据间的“贫富差距”。我们推荐对数据进行归一化;
③点密度为预设的数据复杂程度,决定了每个点附近最多相邻点的数量,在样本较多时,可适当降低点密度使聚类效果更清晰;在样本较少时,可提高点密度使分群内部的点更集中;
④选择行列绘图:选择行时以一行的数据为一个降维数据点进行绘图,选择列是以一列的数据为一个降维数据点进行绘图,当选择项与分组文件的样本名称不同时会导致绘图失败;
⑤修改不同样本点的颜色、大小和透明度;
⑥自定义坐标轴范围;
⑦选择是否在图形中显示分组名称;
(5)图形解读:图中一个点代表一个样本,以样本在二维平面的聚集程度反映样本间的相似性,样本越聚集在一起,说明样本越相似。
Q1. 上传的数据需要保存成什么格式?文件名称和拓展名有没有要求?
OmicShare当前支持txt(制表符分隔)文本文件、csv(逗号分隔)文本文件、以及Excel专用的xlsx格式,同样支持旧版Excel的xls(Excel 97-2003 )格式。如果是核酸、蛋白序列文件,必须为FASTA格式(本质是文本文件)。
文件名可由英文和数字构成,文件拓展名没有限制,可以是“.txt”、“.xlsx”、“.xls”、“.csv”“.fasta”等,例如 mydata01.txt,gene02.xlsx 。
Q2. 提交时报错常见问题:
1.提交时显示X行X列空行/无数据,请先自查表格中是否存在空格或空行,需要删掉。
2.提交时显示列数只有1列,但表格数据不止1列:列间需要用分隔符隔开,先行检查文件是否用了分隔符。
其它提示报错,请先自行根据提示修改;如果仍然无法提交,可通过左侧导航栏的“联系客服”选项咨询OmicShare客服。
Q3. 提交的任务完成后却不出图该怎么办?
主要原因是上传的数据文件存在特殊符号所致。可参考以下建议逐一排查出错原因:
(1)数据中含中文字符,把中文改成英文;
(2) 数据中含特殊符号,例如 %、NA、+、-、()、空格、科学计数、罗马字母等,去掉特殊符号,将空值用数字“0”替换;
(3)检查数据中是否有空列、空行、重复的行、重复的列,特别是行名(一般为gene id)、列名(一般为样本名)出现重复值,如果有删掉。
排查完之后,重新上传数据、提交任务。如果仍然不出图,可通过左侧导航栏的“联系客服”选项咨询OmicShare客服。
Q4.下载的结果文件用什么软件打开?
OmicShare云平台的结果文件(例如,下图为KEGG富集分析的结果文件)包括两种类型:图片文件和文本文件。

图片文件:
为了便于用户对图片进行后期编辑,OmicShare同时提供位图(png)和矢量图(pdf、svg)两种类型的图片。对于矢量图,最常见的是pdf和svg格式,常用Ai(Adobe illustrator)等进行编辑。其中,svg格式的图片可用网页浏览器打开,也可直接在word、ppt中使用。
文本文件:
文本文件的拓展名主要有4种类型:“.os”、“.xls”、“.log”和“.txt”。这些文件本质上都是制表符分隔的文本文件,使用记事本、Notepad++、EditPlus、Excel等文本编辑器直接打开即可。结果文件中,拓展名为“.os”文件为上传的原始数据;“.xls”文件一般为分析生成的数据表格;“.log”文件为任务运行日志文件,便于检查任务出错原因。
Q5. 提交的任务一直在排队怎么办?
提交任务后都需要排队,1分钟后,点击“任务状态刷新”按钮即可。除了可能需运行数天的注释工具,一般工具数十秒即可出结果,如果超出30分钟仍无结果,请联系OS客服,发送任务编号给OmicShare客服,会有专人为你处理任务问题。
Q6. 结果页面窗口有问题,图表加载不出来怎么办?
尝试用谷歌浏览器登录OmicShare查看结果文件,部分浏览器可能不兼容。