



 扫码支付更轻松
扫码支付更轻松

目前有很多的数据库都存储了蛋白序列,在各个数据库之间,或者是在某个数据库中,蛋白序列有大量冗余。因此,NCBI构建了非冗余蛋白序列数据库--NR(Non-Redundant Protein Sequence Database),数据来源于GenPept、Swissprot、PIR、PDF、PDB和NCBI RefSeq,是默认的蛋白比对数据库。对于所有已知的或可能的编码序列,NR记录中都给出了相应的氨基酸序列(通过已知或可能的读码框推断而来)以及专门蛋白数据库中的序列号。NR库相当于一个以核酸序列为基础的交叉索引,将核酸数据和蛋白数据联系起来。
输入文件
1.选择文件
输入fasta格式的核酸或蛋白query序列或上传fasta格式的query序列文件。
2. 选择物种
选择NR数据库的数据集
输出结果
1 注释结果
表1 注释信息统计表
2. 注释结果统计
1)将注释上的与注释不上的序列数目进行统计并画饼图。
表2 注释结果数目统计表
图1 注释结果数目统计饼图
2)E值分布统计
E值是指期望数据库中具有某一统计学意义配对序列的值,可理解为比对的假阳性率。E值越小,结果越可靠。对E值分为5个范围进行统计,并画饼图。
表3 E值分布统计表
图2 E值分布统计饼图
输出结果说明
表1 注释信息统计表
Query_id Unigene序列的ID号
Query_length Unigene序列的长度
Query_start 比对上的部分在 query序列上的起始位置
Query_end 比对上的部分在query序列上的终止位置
Subject_id 比对到NR数据库中序列名
Subject_length 比对上的部分在NR序列上的长度
Subject_start 比对上的部分在 NR序列上的起始位置
Subject_end 比对上的部分在 NR序列上的终止位置
Identity(%) 比对的相似性(百分比)
Align_length 比对上的长度
Gap Gap 的数目
E_value 比对的 E值(E值越小,可信度越高)
Score 比对的打分(打分越高,可信度越高)
Subject_annotation NR序列的描述
表2 注释结果数目统计表表头解释
Total sequence number 输入的所有序列数
Annotation sequences 注释上的序列数
Without annotation sequences 没有注释上的序列数
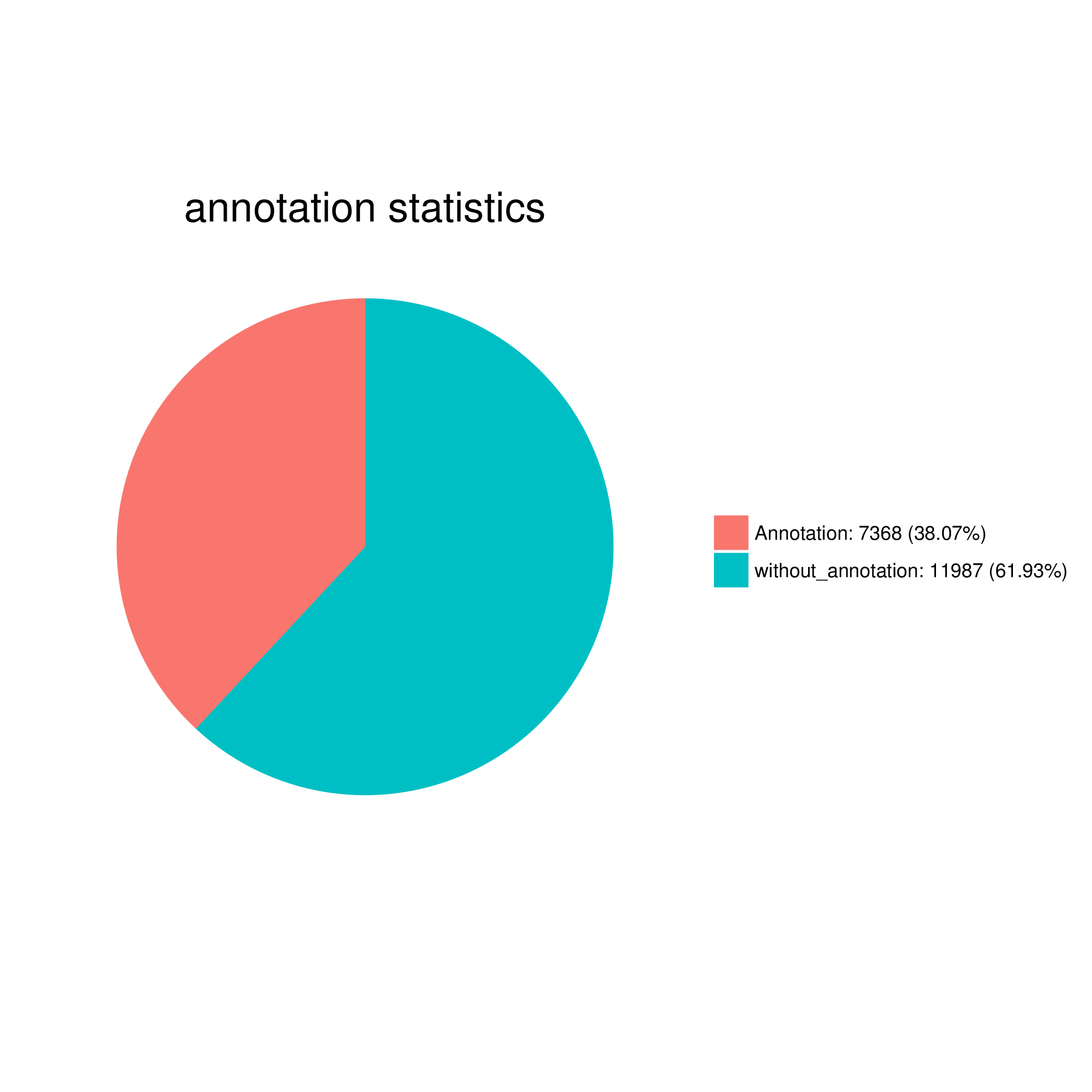 图1 注释结果数目统计饼图
图1 注释结果数目统计饼图
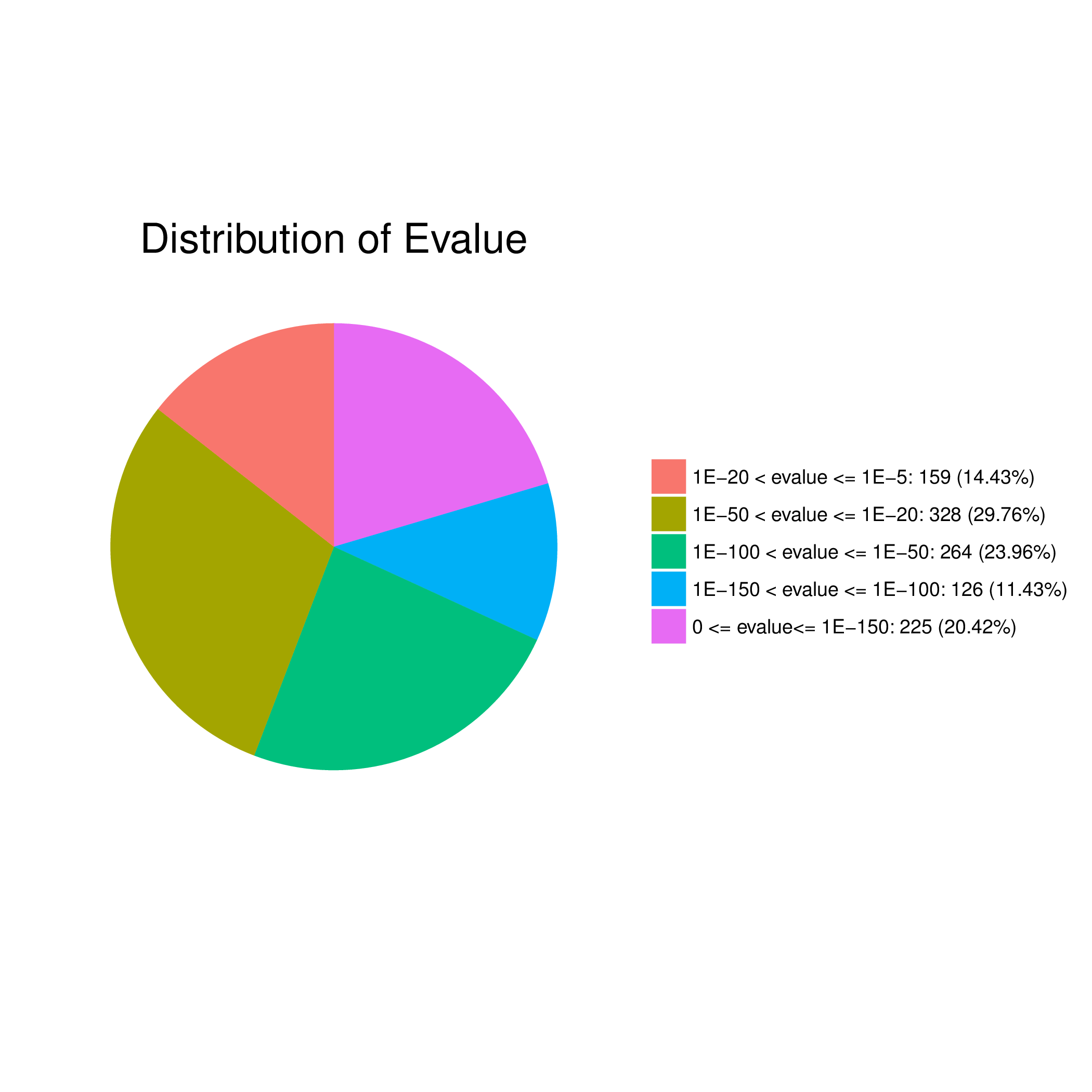
图2 E值分布统计饼图
Q1. 上传的数据需要保存成什么格式?文件名称和拓展名有没有要求?
OmicShare当前支持txt(制表符分隔)文本文件、csv(逗号分隔)文本文件、以及Excel专用的xlsx格式,同样支持旧版Excel的xls(Excel 97-2003 )格式。如果是核酸、蛋白序列文件,必须为FASTA格式(本质是文本文件)。
文件名可由英文和数字构成,文件拓展名没有限制,可以是“.txt”、“.xlsx”、“.xls”、“.csv”“.fasta”等,例如 mydata01.txt,gene02.xlsx 。
Q2.注释工具的任务一般要跑多久?
注释工具的任务时长一般与提交的序列条数成正比,且不同工具耗时也差异很大。例如GO功能注释近一年来所有任务平均时长约为2天,而NR注释工具近一年来所有任务平均时长约为3小时。一般情况下,如果任务耗时超出一周可联系OS客服,发送任务编号给OmicShare客服,会有专人为你处理任务问题。